As mentioned in our last blog post, the Opterna prototype is now up and undergoing user-experience testing. When we have been out presenting to various groups recently, we have been asked “so what is the crosswalk between Open and Opterna”? This is a great invitation to explore how open and open pedagogy have informed the development of Opterna, so let’s dig in!
When we talk about “open” in education, we often think of open textbooks — freely available, openly licensed resources that remove cost barriers for students. But what happens when you bring generative AI into the picture? Opterna offers a case study of trying to embed open principles into an AI-powered learning support experience designed for students and educators.
Opterna is an AI-powered study companion built to work alongside books published in Pressbooks. At first glance, it might look like any chatbot designed to help students study. However, one of the things we set out to do when co-designing Opterna was to use open as a design philosophy to guide our decision making and allow for a project where “open” has been woven into design and functionality.
To do this we drew on several established frameworks including the traditional 5R permissions of OER (retain, reuse, revise, remix, redistribute) made popular by Wiley (2014), Sinkinson’s (2018) values of open pedagogy, Jhangiani’s (2019) 5Rs for open pedagogy, and more recently Clarke-Gray’s (2025) New 5Rs of Open, which foregrounds social justice dimensions as captured in the categories represent, resist, repair, refuse, and rise up. With these frameworks providing the backbone, we ran possible feature sets and design decisions for Opterna against Hegarty’s (2015) eight attributes of open pedagogy, to ensure that what was created reflected, as much as possible, the values core to open pedagogy.
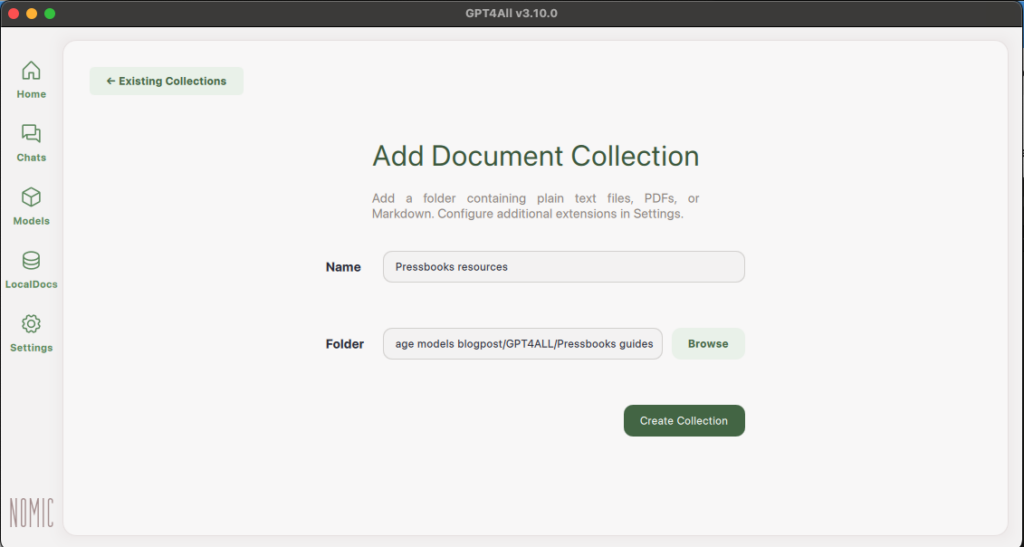
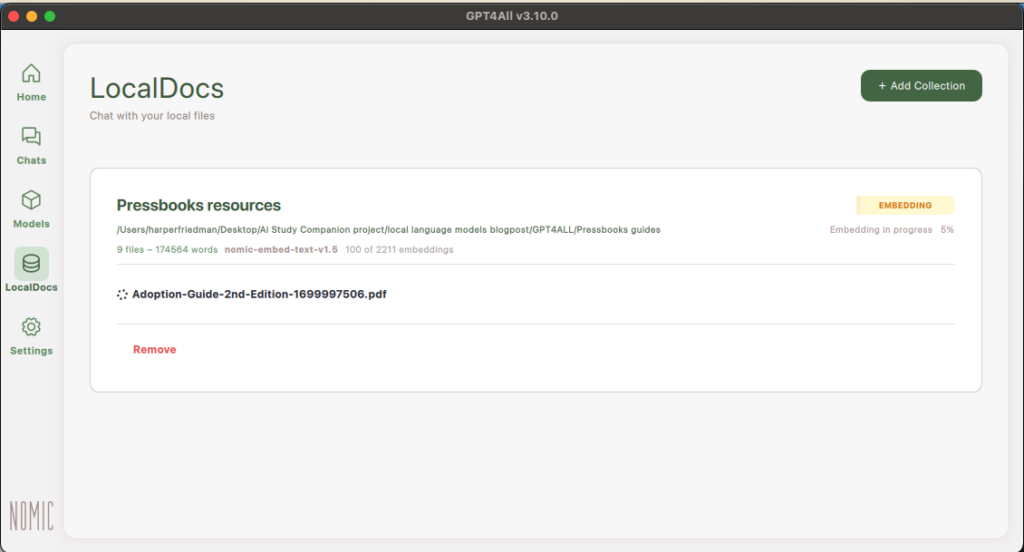
All of this translated into actual features of Opterna in several tangible ways. For example, Opterna is built on openly licensed content — 25 textbooks from the B.C. Open Collection by BCcampus — meaning the knowledge base itself honours the open licensing approach and in doing so, was able to address several privacy and trust concerns raised about generative AI. We also reached out to the authors of these textbooks to make sure they were aware of this new use of their work and provided them with an opportunity ask questions about how their work would inform Opterna, an example of Clarke-Gray’s concept of repair (2025).
In keeping with the traditional 5 permissions of open educational resources, the AI Study Companion source code is available on GitHub under a highly permissive software license that allows other institutions and developers to adopt and adapt it with minimal restrictions. As part of the feature set of Opterna, we intentionally did not add a log-in feature to ensure no personal information would be collected. Privacy and ethical use considerations were baked into the design from the start, and a participatory design-based action research project accompanies this project, investigating how open GenAI tools can be implemented effectively and responsibly in higher education.
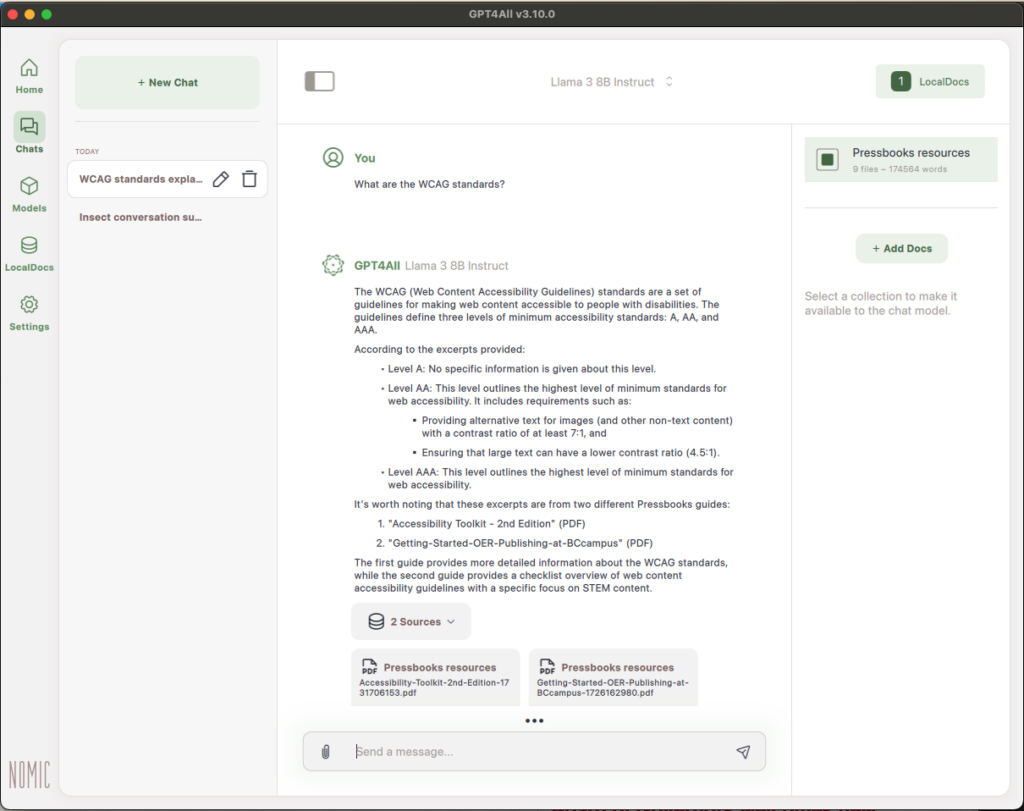
Opterna embodies open pedagogy through its emphasis on student agency and choice. Learners can select the level at which they engage with content — introductory, intermediate, or advanced — and choose their post-secondary level. They can edit pre-populated prompts, create their own, generate their own examples, and build a personal collection of outputs that can be shared with others. The dialogical chat interface, grounded in Socratic questioning, positions the student as an active co-constructor of knowledge rather than a passive consumer.
For instructors, Opterna offers a distinct view with different functionality, along with editable sample prompts and multiple output formats including practice questions, flashcards, FAQs, and audio output. This variety reflects Universal Design for Learning (UDL) principles and allows for some customization and choice within the design constraints of the build.
Through the iterative process of co-creating Opterna with UBC Cloud Innovation Centre (UBC CIC), we developed a draft framework for ethical AI that we used on this project. This framework is centred around values such as trust, human connection, sharing (openness/the commons), access, learner agency, critical engagement, and inter-connectedness.

The Opterna project is still unfolding, with research, testing, workshops, and resource development planned through 2028. But it already demonstrates something important: that “open” in the context of AI, similar to open in the context of OER’s, isn’t just about licensing or access. It’s about student agency, thoughtful design, community participation, and a willingness to share not just products, but processes.
Written by: Dr. Elizabeth Childs
Learn more at the BCcampus Open GenAI Project page or visit the blog at opengenai.opened.ca.